![]() I love Scrapebox, it’s one of my absolute favorite SEO tools over the years. Recently it has been updated to version 2.0. Well I’m one of those resistant to change people , I spent 5+ years using the same interface so you can imagine I wasn’t pumped about trying a new one.
I love Scrapebox, it’s one of my absolute favorite SEO tools over the years. Recently it has been updated to version 2.0. Well I’m one of those resistant to change people , I spent 5+ years using the same interface so you can imagine I wasn’t pumped about trying a new one.
I’ll get there eventually, but in the mean time let’s go over some of my favorite uses for Scrapebox in my day to day grind. This is my list of totally awesome shit you can do with Scrapebox beyond the obvious.
Contents
Analyze internal links
This is actually an entire post in my drafts but I’m shortening it here. You can use the broken link checker addon with a slight tweak to check how your internal linking.
Step 1. Go grab your sitemap, I’m using yoast so it’s super easy.
Now select everything from your sitemap, your CPT, taxonomy, or whatever you’re trying to analyze and then copy it.
Now open excel and use the paste special function to paste all that junk into a spreadsheet.
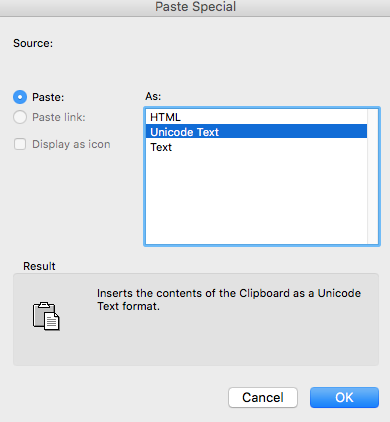
So handy ^^
In the broken link checker settings adjust them like this:
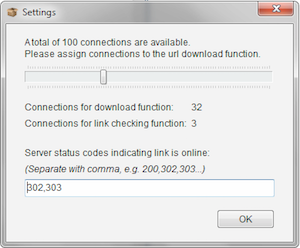
You see I removed the “200” status code that is normally in there. This will make it identify working links as broken and pull them all for you. Take the resulting csv and analyze.
Page scanner for URLs that already link to you
The page scanner has so many uses it’s crazy but this is the first that came to mind. Say you have a big list of prospected URLs for some sort of outreach, wouldn’t it be an awkward email if you already have a link from the page? Well simply use the page scanner and create a footprint with your root domain. Or maybe you want to avoid pages linking to a certain domain. How about scanning for a certain CMS or version of a CMS? This addon has endless possibilities.
Remove containing and not containing from file
This feature is one of the most frequently used for me. You can use the simple version and just filter out one line or you can do it based on an entire file. Say I wanted to filter only URLs that are .edu, I’d use this:
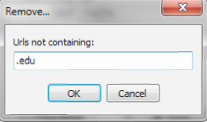
To get more advanced use the remove from a file that either contains or doesn’t contain. Let’s say we want to filter down to only domains that are .com, .org, and .net.
Put that in a file and remove all that don’t contain. Boom, it’s like magic.
Broken link building
I already covered the exact process I developed for broken link building using Scrapebox and excel. It’s awesome and it works. If you haven’t read, bookmarked, and sent a link to all your best friends then shame on you.
Scrub email list for already blasted
This is a cool trick I thought of out of necessity one day. It goes back to the remove from file feature but with a slight twist for emails. Let’s say you’re midway through a campaign and have already blasted a few hundred prospects. Now after you scrape some more you want to make sure you remove the ones you’ve already hit.
The first step is we need to remove the user @ portion from he emails to just have a list of root domains. We can do this easily in excel, just use the text to columns function.

Then tick “other” and put the @ symbol in.
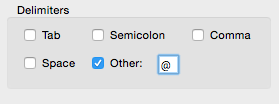
Shazam, you just separated the root domains. Now take those and paste them into a file, something like: “Dont-spam-these-people-again.txt”
Now take your list of new potential emails and paste them directly into the URL harvester. It’s totally fine to just past email@domain.com in there, it will format it with http://email@domain.com
Don’t worry, we’ll just remove that when we’re done. Now use that endlessly baller remove all that contain form a file function and select the file with the root domains. There you go, now just find and replace the “http://” with a blank for your ready to go.
Scrape keywords like a boss
If you’re one of those keyword junkies then Scrapebox can really help you turn up the intensity. The keyword scraper, I’ve mentioned it before but it seems a lot of people overlook its power.
For starters you can use the a-z merge feature to get started.
scrapebox tips a
scrapebox tips b
etc.
A more advanced technique would be using some other things like “how to”, “Buy”, “where to find” etc depending on what your hustle is. Also again we can get gangster with filtering from a file just like we can with URLs.
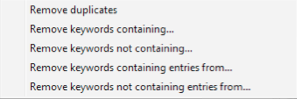
Come to think of it, I’ve almost made my head explode trying to get Vlookup in excel to do a similar thing. Scrapebox to the rescue again.
Grab emails onpage
Not the cleanest way to get contact info but surely it has its uses. Click grab, grab emails from local list. This will literally just scrape all the pages for any available emails.
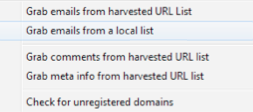
Remember, ANY emails so even a bunch of spam ones will get grabbed if they are there. So you want to use it accordingly, like filter down to only contact pages and grab from those.
For a bit more accuracy you can use URL profiler for this as it will return the data in csv format vs just one big confusing list.
Check for available domains
In both the keyword scraper and the URL harvester you have the ability to bulk check for available domains. Too bad Scrapebox can’t build a time machine for you to go back like 5 years and register a shitload of EMDs. Either way it’s still useful and I needed to add one more thing to this list.
Removing spammy domains from a list
That remove that contains feature is sure getting some mileage isn’t it? Let’s say you have a big list of URLs you’re prospecting, maybe some competitor links you want replicate. Who knows, maybe someone neg SEO’d them so there is a bunch of spam to sort out. We could make a file on our desktop containing some popular spammy words without spaces removed and .com added at the end.
spamkeyword.com
etc.
Find and replace ” ” with “” then use excel =A1&”.com” to format them.
Then go ahead and remove all containing those.
Remove dupes from a big ass list
Sure you can remove duplicates in excel but a really big list could cause you some issues. Scrapebox has it’s limits also but should be plenty for most people. And back to the keyword scraper, don’t forget it allows you to filter keywords just like URLs. Let’s say you have a big list of existing keywords you’ve already published content around and you’re trying to isolate new potential ones. This is your saving grace.
Use with URL Profiler
A really nice tool I’ve recently added to my arsenal to compliment Scrapebox is URL profiler. The main things I’ve been using it for is whois info, social shares, the redirect check, and basically anything SB can’t grab or has a tendency to grab inaccurately.
That’s all for now but only because I need to get back to work. I could literally go on for days with different Scrapebox tips and tricks. My goal is to reference back here over time and add some of the million things I’m forgetting. Not so much my processes but the quick shortcuts you can use to speed up your own processes. And lastly if you have something worth contributing to this, hit me up and I might make your contextual dofollow backlink dreams come true.
Where is Jacob King? Who aré you? I found your blog a few months ago and i was waiting several days for a new post, and Now 1 every day with a lot of actionables tips.
Thank you for your time to share all this tips.
And sorry for my english.
PS. I guess that the gold man pay the Bill.
I just started using scrapebox again after 2 years and its on SC2 now.Have you used the latest version?
I have, it’s pretty.
On the Check for available domains. You can set up custom date ranges in yahoo/bing. sucks that it’s so hard to scrape google these days. any tips on that?
That was nice. Instead of targeting others, target yourself to improve your site. Thanks Jacob King for tips on how to improve your sites