 The idea of broken link building is pretty cool. You find some relevant pages with broken links, email the person and tell them about the broken links, then ask them to link to your shit instead.
The idea of broken link building is pretty cool. You find some relevant pages with broken links, email the person and tell them about the broken links, then ask them to link to your shit instead.
Sounds easy right? Yeah wait until you try to scale it. Well a project came across my desk that was just way too much of slam dunk for this tactic. And so I dove in and found myself banging my head against the wall trying to get everything stream lined. Now that I’ve figured it out I’m ready to share the juicy details. So let’s get started. It’s best to use an example so let’s assume I’m trying to find broken link opportunities for my blog, the obvious places to start are links pages and blog lists. Now I’m going to grind this out, every niche is going to be slightly different. You’re just going to have to put in the effort like I’m about to.
Contents
Ok so we’re going to gather targets two ways, by scraping Google and by using ahrefs on some authority sites in our niche.
The Scrape
Let’s start with scraping. Here’s a sample of some obvious footprints:
inurl:links
inurl:links.htm
inurl:links.php
These are good but they aren’t going to get us that far. Here is a list of some more footprints I found in the other broken link building guides. Some of them are going to return us a bunch of crap so we’ll have to really filter our results. We really need to tailor them for what each specific case.
Right away there is a problem using the inurl:links footprint since there are so many posts about “building links”. You see how each case can be a bit different? Usually this footprint is quite effective but for this case it’s crap.
Oh and be prepared to get nailed with this every 2 seconds because Google is such a tight ass about automated queries these days. Thanks Google you bastards.
So I’m playing around with some stuff like this and doing a bit better.
inurl:blogs & inurl:list “seo”
inurl:blogs & inurl:favorite “seo”
inurl:blogs & inurl:top “seo”
Of course change up the main keyword from “seo” to “marketing”, “link building”, etc. hitting all the root phrases.
Bonus tip: If you want to check if a large quantity of footprints return lots of results you can use the Scrapebox Google results checker add-on. This won’t necessarily tell you if a footprint is good since even a bad footprint can still return lots of results, but it will tell you there are enough results to actually scrape.
And if you had an SEO related tool to promote, of course you could go hard with:
inurl:tools “seo”
inurl:tools & inurl:free “seo”
As much as people would like their hand held through this part, like I said each niche can be a bit different. This is not something that should take 30 minutes. You should spend hours on it and truly harvest a large list. It’s a numbers game with this technique so why not set yourself up to win and do it right.
Competitor Backlinks
Now this approach rocks, especially if all that scraping stuff makes your head hurt. Although being good at scraping is crucial for SEO IMO, so don’t short change yourself.
Using some filtering directly in ahrefs we can find some good targets. This can also be done with excel.
To get started I just popped in seomoz.org and navigated to the backlinks tab. Next all I did was use the search term “seo blogs” and boom I got myself some targets.

Note: If you only have a Majestic account, you’ll have to export the backlinks from there and filter in excel.
Filtering Your Results
Now that you have some targets both from scraping and competitor links, it’s not so simple as let’s just email all these and hope for the best. For starters, how do we even know all these domains are ones we want links from? Currently I’m use Majestic Trust flow as my baseline metric, but in this case I would check the root domains. We can do this using Scrapebox. Start by taking your list of potential targets and trim them to the root domains.
Here’s a link to a spreadsheet with the data I’m working with so you can follow along.
Now upload that list to the Majestic bulk checker, after you export the results sort Trust Flow from large to small.
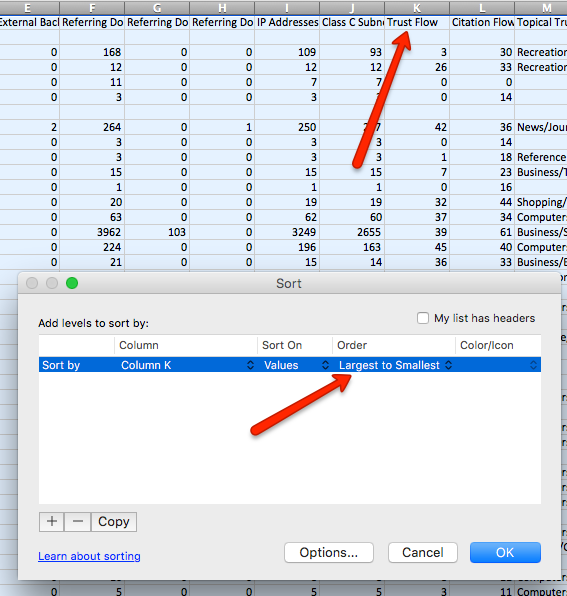
Now the cut off point is up to you, I’d go around TF 20+
Select all those root domains with your desired TF and paste them into a file on your desktop. Now grab that list of broken link targets again and re-paste them into Scrapebox.
Use the “remove all that don’t contain from file” function and select the file with those high TF root domains.
Shazamm, you’ve isolated the strongest domains.
Not done yet though, we need to run a few more checks. Forgive me if this order is a bit off haha, I’m on a roll here.
Let’s go ahead and get rid of any pages already linking to us because that would be a super awkward email. I’m going to use the Scrapebox add-on “page scanner” for this. Click Add New footprint.
Simply set it up like this:
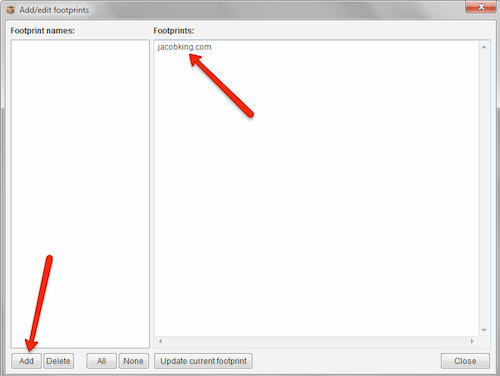
Now save and load URLs from the Scrapebox harvester which are your high TF sorted targets. Run that beast. Export the results and you’ll have 3 files; found, not found, and error. Looks like I’m not that popular cuz zero we’re found :-( Take that “not found” file and you’re ready to move on to the next part.
Yet another check we can run is the outbound link checker add-on. This will help us quickly filter out the pages that have very few outbound links (OBLs) which are likely a waste of our time. Especially if our scrape has gathered some pages that may not be exactly what we’re looking for. For example if a page has only 2 OBLs it’s unlikely that we won’t get the person to add a link. This is one of the few times where more OBLs is a good thing, well within reason. We want to avoid stuff with probably like 100+, that’s getting a little crazy. If you want you can filter entries by more than xxx right here within Scrapebox.
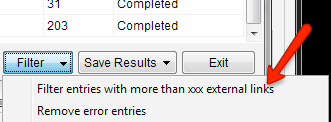
Save yourself the step in excel.
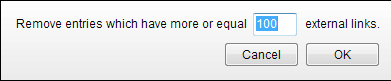
Export as xls then sort that external link column from high to low. There you have it, you’ve just filtered down your list into something reasonable to work with. Obviously you want to do this on a much larger scale, like as big as you can go without crying from boredom.
Check them Broken Links
Jeez I almost forgot, what about the broken link checking?! Well I guess I was saving the best for last, the order might seem a bit backward but I prefer it this way so my broken link file isn’t a total cluster f#^k. So feel free to reorder this process as you so feel.
Open the “Broken Links Checker” add-on in Scrapebox. This is going to to help us turn on the beast mode on a bit. No browser extensions, good god the last thing I would recommend is manually doing this one by one.
Note: Since you’re not scraping Google or doing any type of submissions you DO NOT need proxies for this. So turn off proxies and just run it on your home IP.
Ok so my settings are default, 10 connections and using the standard status codes to check for links being online (200, 302, 303). If your list is huge, you can ramp up the connections. Just be aware your internet connection will slow to a drip while SB is throttling the shit out of it. When complete, export the dead links only and it’s time for the real fun to begin.
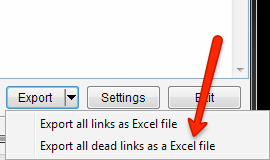
Now after this is finished you’re going to run into a problem, the resulting excel file is not exactly formatted in a friendly way for the following steps. In order to import this data into Buzzstream (my weapon of choice for email outreach) we need to work some magic. First we need to insert a new row above each source URL in column A. The only way to accomplish this is with an excel macro. Don’t worry, it’s not as intimidating as you think, plus I’ve already tracked down the code.
You’re going to need to create a new macro and add this code:
Sub Macro1()
'
Dim lngLastRow As Long
Application.ScreenUpdating = False
For lngLastRow = Cells(Cells.Rows.Count, "A").End(xlUp).Row To 2 Step -1
If InStr(Cells(lngLastRow, "A"), "http") > 0 Then
Rows(lngLastRow).EntireRow.Insert
End If
Next lngLastRow
Application.ScreenUpdating = True
End Sub
Make sure the name of your macro is correct, in my code example it’s “Macro1”. Here are the results of running this beast:
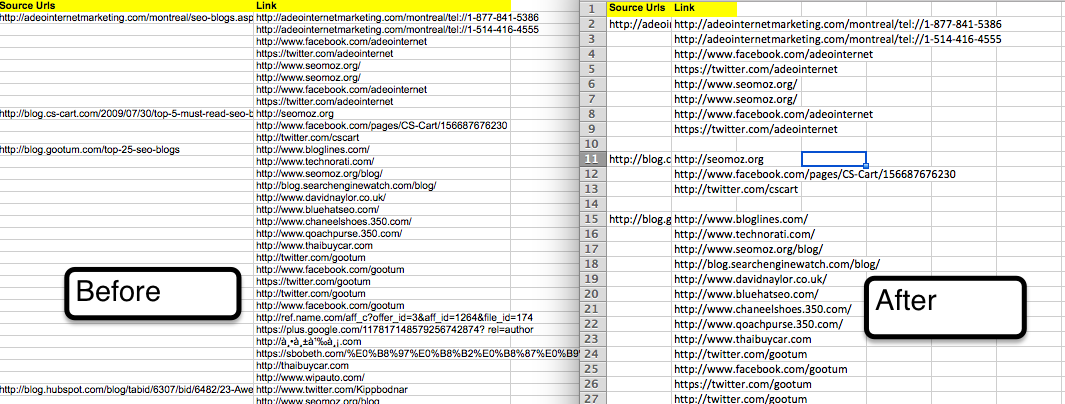
Quick Side Note: I just noticed an issue with this data, for some reason Twitter.com is being returned as broken, so we definitely should have filtered that out. Also I’m realizing some of these broken links are from blog comments which are obviously not what we want. This is a new issue for me so I’m not sure of the exact work around. We’d need to isolate only the dofollow links though somehow to avoid the comment links.
Still not done, we need to comma separate the list of broken links and remove the empty spaces. Take that entire column B, paste it to a plain text file, then paste it into Microsoft word. Click the little thingy to show paragraph marks.
![]()
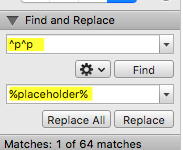
Now find and replace 2x paragraph marks with a placeholder. So find “^p^p” and replace it with “%placeholder%”. This will help us preserve the blank line we made.
Next we want to find and replace the single paragraph marks with a comma.
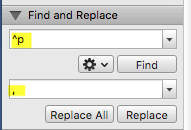
Last step, find and replace the %placeholder% with a blank line. Boom you’ve got all your broken links comma separated in a neat list.
Note: You can use ” and ” if you’d prefer that over the comma separated format.
Back to column A though, we have a ton of blank spaces. Select it, press F5, click special, and select blanks.
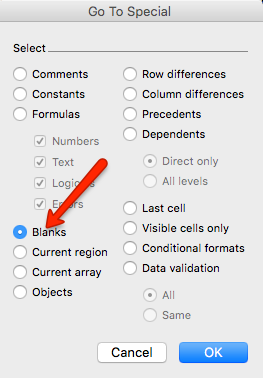
Now delete them and have the rows shift up.
And there you have it, my excel file is FINALLY ready to move on to phase 2 and gather some contact information. This is getting insane, I know.
Get the Contact Info
Now that everything is all formatted nice and pretty we need some email info. My process is like this:
1. Import the URLs into Buzzstream and see what it comes up with.
2. For the emails I still can’t find, you can use URL Profiler (which is totally badass) and your myaddr account. This will pull any public whois info and you can try that.
3. Still nothing? Well you can try a more brute force approach, just take the common admin@, info@, webmaster@, common emails and use a verification service to check which go through. Then bomb on those.
4. Pay a VA to find it. Also isolate the ones with contact forms, you’ll have to manually spam those or rig Scrapebox or uBot to hit them.
Sorry nothing revolutionary there, Buzzstream actually does a really good job at crawling the contact page for an email.
Unleash the Outreach Hounds
Your completed excel file should have 4 columns, Email, Root Domain, Page with Broken Links, List of Broken Links. Once you get there you’re ready to import that beast into Buzzstream and start lighting up some inboxes.
Don’t over complicate this, send an email first asking if they still maintain the site.
Subject: Found Broken Links on your site
Body: Hey there, I was just clicking around on your site and noticed some broken links. Do you still manage [Root Domain]?
If so let me know and I’ll show you what I’m talking about.
-J
Now you wait. When they email back you drop the hammer on them. Use a reply like this and if you have the time personalize it real quick and you’ll do much better:
RE:
Hey James!
So this is the page I was clicking around: [Page with Broken Links]
And these are the links that I noticed that aren’t working:
[List of Broken Links]
That should help you fix them quickly :-)
Also while you’re in there it would be awesome if could drop a link to the most baller SEO blog on the Internet holmes!
This is my homepage – https://www.jacobking.com/
You’re rankings will forever be higher if you link to me.
Take it easy buddy!
-J
Obviously I’m not an expert here, there’s plenty of stuff out there on how to craft higher converting templates. Put in some effort to making something quality and try to tailor it as much as you can to your niche. If you just use a generic approach then the placement rate will be much lower, so don’t get lazy!
For the people who don’t reply, spam them again with another email. Hey are you alive? Did you miss my last email? Then eventually you can try to find an alternate email and hit that or eventually write them off. Keep yourself a running list of domains you’ve already found and hit so you can filter them out when you do new prospecting. Just use the Scrapebox “remove URLS that contain entries from” feature to scrub your list.
Final Thoughts
I probably left out a ton of shit and we’re already past 2,000 words. The important part is you know how to gather lots of targets and convert them into manageable format. This will undoubtedly set you apart from your competition if they are checking pages one by one. Also as far as buzzstream goes you still need to do some work sending the emails. It’s not a huge deal, but I rigged uBot to click the send button for me every 60-120 seconds. That way I can do other things while it sends the emails for me. If you’re interested let me know in the comments and I’ll do quick update or post on how to set this part up.
The replies I do by hand because I think it’s worth the effort. But remember you’re just clicking a button and inserting your template with all the info so it’s not too bad. Also I take the list of comma separated broken links and reverse them to a straight list with MS word like I showed above. I do this because it looks weird sending a huge block of links comma separated. Unfortunately we need them this way to for the template to work. Speaking of which, this is the csv file I’m using, super simple. Just make sure you create the custom fields in Buzzstream first for it to work.
Well there you have it, broken link building beast mode style, now go dominate!!
This is the best guide to the Broken Link Building that i have read!
(First!!! AHAHAH!!)
Will this outreach strategy work with an affiliate site like an amazon affiliate for example? I’m sure it has to have quality content and don’t look spammy, but do other webmasters really link to you so easy with by just an outreach that makes this strategy worthwhile your time?
Good question, I guess I should put a little disclaimer or something. If you’re site is spammy at all then the results from this will suck ass. Just like an amazon affiliate site yes, I suppose you might land a few links but not going to crush it.
This is more for trying to link something up that is actually worth linking up. Or you could try implementing this at first with a new domain, try and get as many links as you can by putting up some BS temporarily, then put up your amazon stuff eventually.
I love this guy !!!
Thanks man
I love you Jacob, you are the best. Do you have some products i’ll byte your hand to purchase from you.
Thanks Jacob, i also read your Scrapbox Guide it was very helpful . :)
Jacob thanks for great information and its very useful for me i am also using screbbox but don’t know these commends
thanks
Well I think your first problem is dropping blog comments with exact anchor text like “SEO services”
Fuck SEO Im here for the comedy..
Hhaha I gotta make sure to keep that flowing strong.
Jacob is thel King when it comes to link building, simply love all your posts!
Great guide!! Being a newbie I got lost at the “seomoz backlink checker” as I cannot seem to find it. I googled it but to no avail. Where can I find the URL for it?
Thanks!
Huh? I used ahrefs backlink tool, just used “Seomoz.org” as an example URL
Thanks Jacob for sharing those tips on fixing broken links. Only problem it was I had a problem concentrating on the blog post because I was laughing so hard thinking about your title. Thanks again!
Hahah yes, was it the new one or old one?
Originally it was “for SEOs that Get Shit Done” and I changed it to “for SEOs That Actually Do Things They Read in Blog Posts”
Nice detailed post Jacob. I just hope the webmasters will accept:)
Bloody hell that has to be just about the most actionable post I’ve read in a long time!
Boom
Hi, Jacob. How do you bulk check Majestic when aiming for thousands of domains? Currently using Majestic now and it’s only limited to 400 URLs per search. Do you do it by 400 url batches or is there a way to automate this? Thanks!
You gotta use the bulk uploader dude.
Love the post. I’m having some trouble checking the backlinks for broken links, Scrapebox just comes up with a bunch of errors instead of actual broken links
Hrmm do you have proxies enabled? Maybe you do with none or some old ones in there.
Also are the URLs https? I’m thinking you just need to untick use proxies.
Hi Jacob,
Thank you for this very useful article. I use most of the tools you mentioned here, and I also like the Check my links Google Chrome extension. You can activate it to quickly scan a web page for broken links. It’s a particularly efficient tool when you are checking a page listing useful links and you would like your link added there. You can easily see if they have a broken link on their web page and then ask them to replace it with yours.
This can be useful when you visit .edu or .org websites because they often have resources pages, and you can scan them for link opportunities with this extension.
Nice bro, yeah let’s do it manually…posting a comment on a post about how to do it near automatic. That makes sense.