 Efficient scraping of Google is arguably one of the best skills an SEO can have. Not just scraping any old bullshit though, being able to effectively drill down and find every last bit of whatever it is that you’re looking for.
Efficient scraping of Google is arguably one of the best skills an SEO can have. Not just scraping any old bullshit though, being able to effectively drill down and find every last bit of whatever it is that you’re looking for.
I’m going to work through an example and scratch the surface to show how hard you can go. Let’s say I’m trying to find SEO blogs that have written about “Scrapebox”
I’m going to start with my favorite operator, inurl:
inurl:scrapebox
Ok so we’ve got some shit about Scrapebox, but we want SEO blogs. Let’s refine it more.
inurl:scrapebox “by”
I added “by” because that’s very common on blogs before the author name.
inurl:scrapebox “by” “blog”
or
inurl:scrapebox “by” “Comments”
We could even add “blog” or “comments” as a lot of people have that text as well.
Lastly we don’t want Scrapebox.com so let’s finish it off.
inurl:scrapebox “by” -scrapebox.com
Note: Don’t worry Google will hit you with a captcha every 2 seconds now days. Just grind through it.
We could also manipulate the date range to past year only for example. And let’s not forget taking scrapebox.com and putting dropping it into ahrefs. You could export all the links and filter out the forums and shit then exclude every URL that contains “scrapbox”, and analyze those to build even more footprints to try and grab everything we’re missing with our current footprint.
Remember to pay attention to the number of results that are returned. If the number is under a few thousand then your footprint is VERY specific. If the results are several million then your footprint is likely too broad. Hit the sweet spot, then merge in dictionary words and stop words to dig deep into the query and extract even more results.
inurl:scrapebox “by” “my” -scrapebox.com
inurl:scrapebox “by” “the” -scrapebox.com
inurl:scrapebox “by” “etc.” -scrapebox.com
I used to use a really large list of stop words but then I reduced it to the most popular ones by “” exact match Google results. You can grab popular stop words for free if you’d like. Yup no email option for once, isn’t that nice? I always keep those handy on my desktop for merging them into a scrape.
Also if you are just doing a quick scrape or don’t have any proxies handy, I have to give a shoutout to this handy bookmarklet. All you have to do is put your settings to display 100 results.
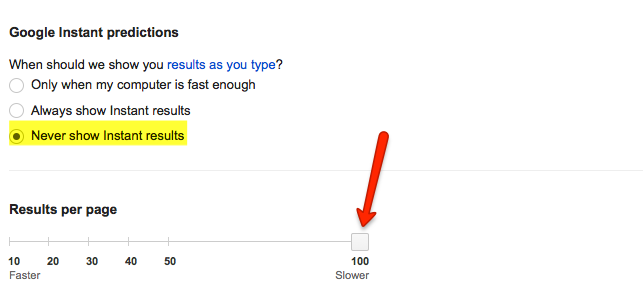
Then you just click the bookmarklet to grab each page of 100 results. I’ve used it a few times, definitely comes in handy.
All it takes is practice and putting in some the effort then you’ll be a scraping master in no time. If you’d like me to walk through building some more footprints just comment below with an idea. Then I’ll try to add it to the post. Until then, happy scraping :-)
Hey Jacob,
Did you know you can export results from Ahrefs Content Explorer?
see screenshot: https://imgur.com/NOowUKH
let me know what you think ;)
Ah very nice, very nice.
Thanks man
I need an advice , i use scrapbox and with private proxy and its shit, i dont have many but google keep block me all time , ( also when i change the proxys to new it happen and use low threads with time wait )
I need help
Does gsa scraper works well with with google scraping ?
What do to ?
Gscraper proxies are pretty bad too, but you can keep scraping on them and eventually get most of the results. I’m using a set of 40 shared proxies in Scrapebox, 1-2 threads.
Nice tips, thanks for all. I have one question – I want to list only url with domain .edu how to list that?
remove all that don’t conatin “.edu” viola!